Image Classification and Recommender System
![]()
Introduction:¶
This project aims to do image classification for Williams Sonoma’s products, then build a recommender system based on image or product title.
The title-based recommender system is like most recommender systems in e-commerce that are mostly text-based and usually rely on a knowledge base and use a keyword matching system. However, this requires online shoppers to provide descriptions of products, which can vary greatly from the sellers’ side to the buyers’ side. The image-based recommender system aims to change the traditional search paradigms from text description to visual discovery. The application of image matching using artificial intelligence in the online shopping field remains largely unexplored. It will be particularly beneficial for a company like Williams Sonoma, for around 70% of the total revenue comes from e-commerce.

# General imports
import pandas as pd
import numpy as np
import glob
import warnings
warnings.simplefilter('ignore')
import seaborn as sns
import requests
import urllib
import cv2
import re
from io import BytesIO
import requests, os
from os import path
from sklearn.model_selection import train_test_split
from tensorflow.keras import regularizers
from keras.layers.core import Dropout
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from wordcloud import WordCloud
from tensorflow.keras.preprocessing.image import load_img,img_to_array
from tensorflow.keras.models import Model
from tensorflow.keras.applications.imagenet_utils import preprocess_input
from sklearn.metrics.pairwise import cosine_similarity
from tensorflow.keras.models import Sequential
from tensorflow.keras import layers, losses
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.metrics import classification_report
from keras.applications import vgg16
from keras.applications.vgg16 import VGG16
from keras.preprocessing.image import load_img,img_to_array
from keras.models import Model
from keras.applications.imagenet_utils import preprocess_input
from PIL import Image
import matplotlib.pyplot as plt
from sklearn.metrics.pairwise import cosine_similarity
from keras.layers import Flatten
from keras.optimizers import Adam
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import linear_kernel
Data Cleaning¶
#set working directory
path = 'C:/Users/linli/Desktop/In progress project/WSI/product_file/'
os.chdir(path)
#find all csv files in the folder
#use glob pattern matching -> extension = 'csv'
#save result in list -> all_filenames
extension = 'csv'
all_filenames = [i for i in glob.glob('*.{}'.format(extension))]
#print(all_filenames)
#combine all files in the list
combined = pd.concat([pd.read_csv(f) for f in all_filenames ])
#export to csv
combined.to_csv( "combined.csv", index=False, encoding='utf-8-sig')
data=pd.read_csv("combined.csv")
data
data=data.reset_index()
data=data.rename(columns={"index":"PID"})
data.head(5)
Exploratory Data Analysis¶
# Checking the unique observations, datatype & null values for every feature
d = {"Feature":[i for i in data.columns],"Number of unique entry" :data.nunique().values ,'Type' : data.dtypes.values, "Missing values" : data.isnull().sum() }
description = pd.DataFrame(data = d)
description
pd.DataFrame(data['category'].value_counts())
# Creating a plot to check class distribution
plt.figure(figsize=(8,6))# Creating an empty plot
count_classes = pd.value_counts(data['category'], sort = True)
ax=count_classes.plot(kind = 'bar', rot=0)
plt.title("William Sonoma product categories")
plt.xlabel("Class")
plt.ylabel("Frequency")
for p in ax.patches:
ax.annotate('{}'.format(p.get_height()),(p.get_x()+0.2,p.get_height()+6)) # Adding the count above the bars
plt.show()

def display_img(url):
"""
This functions takes the image url and return the picture of the image
"""
# we get the url of the apparel and download it
response = requests.get(url)
img = Image.open(BytesIO(response.content))
# we will display it in notebook
return plt.imshow(img)
display_img(data['image'][1])
print(data['category'][1])

display_img(data['image'][100])
print(data['category'][100])

display_img(data['image'][200])
print(data['category'][200])

display_img(data['image'][300])
print(data['category'][300])

plt.rcParams['figure.figsize'] = (10,10)
plt.style.use('fast')
wc = WordCloud(background_color = 'green', width = 1500, height = 1500).generate(str(data['title']))
plt.title('Description of the product titles', fontsize = 20)
plt.imshow(wc)
plt.axis('off')
plt.show()

#for idx, row in data.iterrows():
# url = row['image']
## response = requests.get(url)
# img = Image.open(BytesIO(response.content))
# img.save('C:/Users/linli/Desktop/In progress project/WSI/product_file/'+ str(row['PID'])+'.jpg')
Part I: Image Classification¶
Idea: given a product photo uploaded by the customer, find the category that this product most likely belongs to. I have 10 categories in my data set in total.
Method explained:
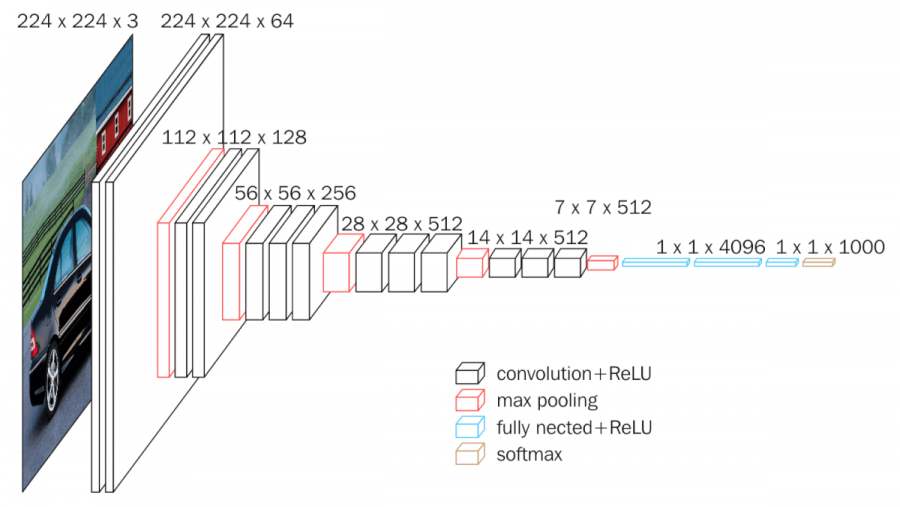
For the image classification task, I use the pre-trained Convolutional Neural Network VGG16. Since my dataset is small, it is better to reuse the lower layers of a pre-trained model because it requires significantly less training data and speeds up training considerably.
VGG16 has a classical architecture, with 2 or 3 convolutional layers and pooling layer, then again 2 or 3 convolutional layers and a pooling layer, and so on (reaching a total of 16 convolutional layers), plus a final dense network with 2 hidden layers and the output layer. It uses only 3 by 3 filters, but many of them.
# creating a function to download the image links from the dataset
def img_array(img):
"""
This function takes in an image and converts the image to an array after resizing
"""
response = urllib.request.urlopen(img)
image = np.asarray(bytearray(response.read()), dtype="uint8")
image_bgr = cv2.imdecode(image, cv2.IMREAD_COLOR)
image_bgr = cv2.resize(image_bgr, (224,224)) # resizing all images to one size
return image_bgr
# Using the above function here to store all the images in the dataset into arrays
image_array=[]
for i in data['image']:
image_array.append(img_array(i))
img_arr=np.array(image_array)
# Converting the response variable into numbers
data['category'][data['category']=='coffeemaker']=0
data['category'][data['category']=='spatula']=1
data['category'][data['category']=='frypan']=2
data['category'][data['category']=='lighting']=3
data['category'][data['category']=='rug']=4
data['category'][data['category']=='glass']=5
data['category'][data['category']=='sofa']=6
data['category'][data['category']=='knife']=7
data['category'][data['category']=='chair']=8
data['category'][data['category']=='bowl']=9
y=data['category'].astype(int)
X_train, X_test, y_train, y_test = train_test_split(img_arr, data['category'], test_size=0.2, random_state=748)
X_train= X_train/255 ## scale the raw pixel intensities to the range [0, 1]
X_test= X_test/255
# Preprocess class labels
from keras.utils import np_utils
# Preprocess class labels
y_train = np_utils.to_categorical(y_train, 10)
y_test = np_utils.to_categorical(y_test, 10)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
from keras.layers import Dense
# define cnn model
def define_model():
# load model
vgg_model= VGG16(include_top=False, input_shape=(224,224, 3))
# mark loaded layers as not trainable
for layer in vgg_model.layers:
layer.trainable = False
# add new classifier layers
flat1 = Flatten()(vgg_model.layers[-1].output)#transforms the format of the extracted features from a 2d-array to a 1d-array of 224*224*3 pixel values.
class1 = Dense(128, activation="relu", kernel_initializer="he_uniform")(flat1)
output = Dense(10, activation="softmax")(class1)
# define our image classification new model
model = Model(inputs=vgg_model.inputs, outputs=output)
# compile model
opt = Adam(lr=0.001)
model.compile(optimizer=opt, loss="categorical_crossentropy", metrics=["accuracy"])
return model
image_classification_model=define_model()
image_classification_model.summary()
history =image_classification_model.fit(X_train, y_train, batch_size=32, epochs=5, verbose=1, validation_split = 0.2)
def plot_accuracy_loss(history):
"""
Plot the accuracy and the loss during the training of the nn.
"""
fig = plt.figure(figsize=(10,8))
# Plot accuracy
plt.subplot(221)
plt.plot(history.history['accuracy'],'bo--', label = "accuracy")
plt.plot(history.history['val_accuracy'], 'ro--', label = "val_accuracy")
plt.title("Training and Validation accurarcy")
plt.ylabel("accuracy")
plt.xlabel("epochs")
plt.legend()
# Plot loss function
plt.subplot(222)
plt.plot(history.history['loss'],'bo--', label = "loss")
plt.plot(history.history['val_loss'], 'ro--', label = "val_loss")
plt.title("Training and Validation loss")
plt.ylabel("loss")
plt.xlabel("epochs")
plt.legend()
plt.show()
plot_accuracy_loss(history)

# Predict the values from the validation dataset
y_pred = image_classification_model.predict(X_test)
# Convert predictions classes to one hot vectors
y_pred = np.argmax(y_pred,axis = 1)
# Convert validation observations to one hot vectors
y_test = np.argmax(y_test,axis = 1)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy : %.2f%%" % (accuracy*100.0))
# Confusion matrix for results
cm = confusion_matrix(y_test, y_pred)
fig, ax= plt.subplots(figsize=(12,12))
sns.heatmap(cm, annot=True, cmap="Greens",linecolor="gray", ax = ax, fmt='g'); # annot=True to annotate cells. 'fmt' prevents the numbers from going to scientific notation
# labels, title and ticks
ax.set_xlabel('Predicted labels');ax.set_ylabel('True labels');
ax.set_title('Confusion Matrix');
ax.xaxis.set_ticklabels(['coffeemaker','spatula','frypan','lighting','rug','glass','sofa','knife','chair','bowl']);
ax.yaxis.set_ticklabels(['coffeemaker','spatula','frypan','lighting','rug','glass','sofa','knife','chair','bowl']);
plt.show()

categories=['coffeemaker','spatula','frypan','lighting','rug','glass','sofa','knife','chair','bowl']
print(classification_report(y_test, y_pred, target_names=categories))
test_labels=y_test.tolist() # converting the y_test into a list
# Creating a function which picks random images and identifies the class to which the image belongs
def get_image_and_class(size):
idx = np.random.randint(len(X_test), size=size) # generating a random image from the test data
for i in range(len(idx)):
fig = plt.figure()
fig.set_size_inches(5,5)
plt.imshow(X_test[idx,:][i])
plt.show()
# Print the class of the random image picked above
if test_labels[idx[i]] == 0:
print('This is a coffeemaker!')
elif test_labels[idx[i]] == 1:
print('This is a spatula!')
elif test_labels[idx[i]] == 2:
print('This is a frypan!')
elif test_labels[idx[i]] == 3:
print('This is a lighting!')
elif test_labels[idx[i]] == 4:
print('This is a rug!')
elif test_labels[idx[i]] == 5:
print('This is a glass!')
elif test_labels[idx[i]] == 6:
print('This is a sofa!')
elif test_labels[idx[i]] == 7:
print('This is a knife!')
elif test_labels[idx[i]] == 8:
print('This is a chair!')
elif test_labels[idx[i]] == 9:
print('This is a bowl!')
get_image_and_class(5)





Part II: Recommender System¶
A: Image-based recommender system¶
Idea: given the photo's features and the category that this product belongs to, calculate similarity scores, and find the most similar products in our database.
Method explained:
For the recommendation step, I use the last fully connected layer in the classification model as feature vectors of images. For any images in the dataset, there will be one corresponding feature vector. And this feature vector will be the input for our recommendation model. The workflow of this step is shown in the following bullets.
• Feature extraction: the classification model is used to identify which category the target image belongs to. Then I extract the input from the last fully connected layer of the classification model as features.
• Input of the model: the feature vector of the target image extracted in the above.
• Similarity calculation: using cosine similarity to calculate similarity scores between the feature vector of the target image and feature vectors of all images in the target category to measure the similarity between image pairs. The larger the cosine similarity score, the more similar the two images are.

• Output: top k images (products) that are most like the target image.
The recommendation engine I build in this project is a content-based method. We look at the product features in a content-based method to recommend other similar products based on product attributes.

# load the model
vgg_model = vgg16.VGG16(weights='imagenet')
# remove the last layers in order to get features instead of predictions
feat_extractor = Model(inputs=vgg_model.input, outputs=vgg_model.get_layer("fc2").output)
# print the layers of the CNN
feat_extractor.summary()
# parameters setup
imgs_path = "C:/Users/linli/Desktop/In progress project/WSI/product_file/"
imgs_model_width, imgs_model_height = 224, 224
nb_closest_images = 5 # number of most similar images to retrieve
files = [imgs_path + x for x in os.listdir(imgs_path) if "jpg" in x]
print("number of images:",len(files))
# load all the images and prepare them for feeding into the CNN
importedImages = []
for f in files:
filename = f
original = load_img(filename, target_size=(224, 224))
numpy_image = img_to_array(original)
image_batch = np.expand_dims(numpy_image, axis=0)
importedImages.append(image_batch)
images = np.vstack(importedImages)
processed_imgs = preprocess_input(images.copy())
# extract the images features
imgs_features = feat_extractor.predict(processed_imgs)
print("features successfully extracted!")
imgs_features.shape
# compute cosine similarities between images
cosSimilarities = cosine_similarity(imgs_features)
# store the results into a pandas dataframe
cos_similarities_df = pd.DataFrame(cosSimilarities, columns=files, index=files)
cos_similarities_df.head()
# function to retrieve the most similar products for a given one
def image_based_recommendations(given_img):
print("-----------------------------------------------------------------------")
print("original product:")
original = load_img(given_img, target_size=(imgs_model_width, imgs_model_height))
fig = plt.figure()
fig.set_size_inches(5,5)
plt.imshow(original)
plt.show()
print("-----------------------------------------------------------------------")
print("most similar products:")
closest_imgs = cos_similarities_df[given_img].sort_values(ascending=False)[1:nb_closest_images+1].index
closest_imgs_scores = cos_similarities_df[given_img].sort_values(ascending=False)[1:nb_closest_images+1]
for i in range(0,len(closest_imgs)):
original = load_img(closest_imgs[i], target_size=(imgs_model_width, imgs_model_height))
fig = plt.figure()
fig.set_size_inches(5,5)
plt.imshow(original)
plt.show()
print("similarity score : ",closest_imgs_scores[i])
image_based_recommendations(files[1])






image_based_recommendations(files[100])






B: Text-based recommender system¶
Idea: if instead given the product title, then calculate similarity scores for the title and find the most similar product titles in my database.
Method explained:
• Data preprocessing: when dealing with text data, we need to convert the text data to numbers that way computer can understand.
I convert the word vector of each title then compute Term Frequency-Inverse Document Frequency (TF-IDF) vectors for each title.
What is Term Frequency-Inverse Document Frequency (TF-IDF)?
Term Frequency: a measure of the frequency of the word in the current document.
Inverse Document Frequency: a measure of how rare the word is across documents, which tells us how significant the term is among the documents.
The higher value of the term, the rarer it is in the document.
• Calculation of cosine similarity between the product titles: since we have used the TF-IDF vectorizer, calculating the dot product will directly give us the cosine similarity score. Therefore, we will use sklearn's linear_kernel() instead of cosine_similarities() since it is faster.
• Build the title-based recommender system: a function is created that takes in the product title and returns the top 10 recommendations. The similarity score is arranged in descending order, and results are given based on the score.
data['title'].sample(5)
#Import TfIdfVectorizer from scikit-learn
#from sklearn.feature_extraction.text import TfidfVectorizer
#Define a TF-IDF Vectorizer Object. Remove all english stop words such as 'the', 'a'
tfidf = TfidfVectorizer(stop_words='english')
#Construct the required TF-IDF matrix by fitting and transforming the data
tfidf_matrix = tfidf.fit_transform(data['title'])
#Output the shape of tfidf_matrix
tfidf_matrix.shape
There are 609 Products and 732 are unique words in the product title.
# Compute the cosine similarity matrix
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)
cosine_sim_table=pd.DataFrame(cosine_sim)
cosine_sim_table.columns=data['title']
cosine_sim_table.index=data['title']
cosine_sim_table
The more similar the title, the higher the cosine similarity score.
#Construct a reverse map of indices and product titles
indices = pd.Series(data.index, index=data['title']).drop_duplicates()
# Function that takes in a title as input and outputs top 10 most similar product titles
def title_based_recommendations(title, cosine_sim=cosine_sim):
# Get the index of the product that matches the title
idx = indices[title]
# Get the pairwsie similarity scores of all product titles with that title
sim_scores = list(enumerate(cosine_sim[idx]))
# Sort the titles based on the similarity scores
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# Get the scores of the 10 most similar titles
sim_scores = sim_scores[1:11]
# Get the titles indices
product_indices = [i[0] for i in sim_scores]
# Return the top 10 most similar titles
return data['title'].iloc[product_indices]
title_based_recommendations('Staub Perfect Pan')
title_based_recommendations('Robinson Clear Glass Pendant')